Defensible capability decisions at scale.
Practitioners — assessors, HR business partners, learning and development leads, coaches, psychologists — use Capable to run the structured work that turns evidence into ratings that hold up under questioning.
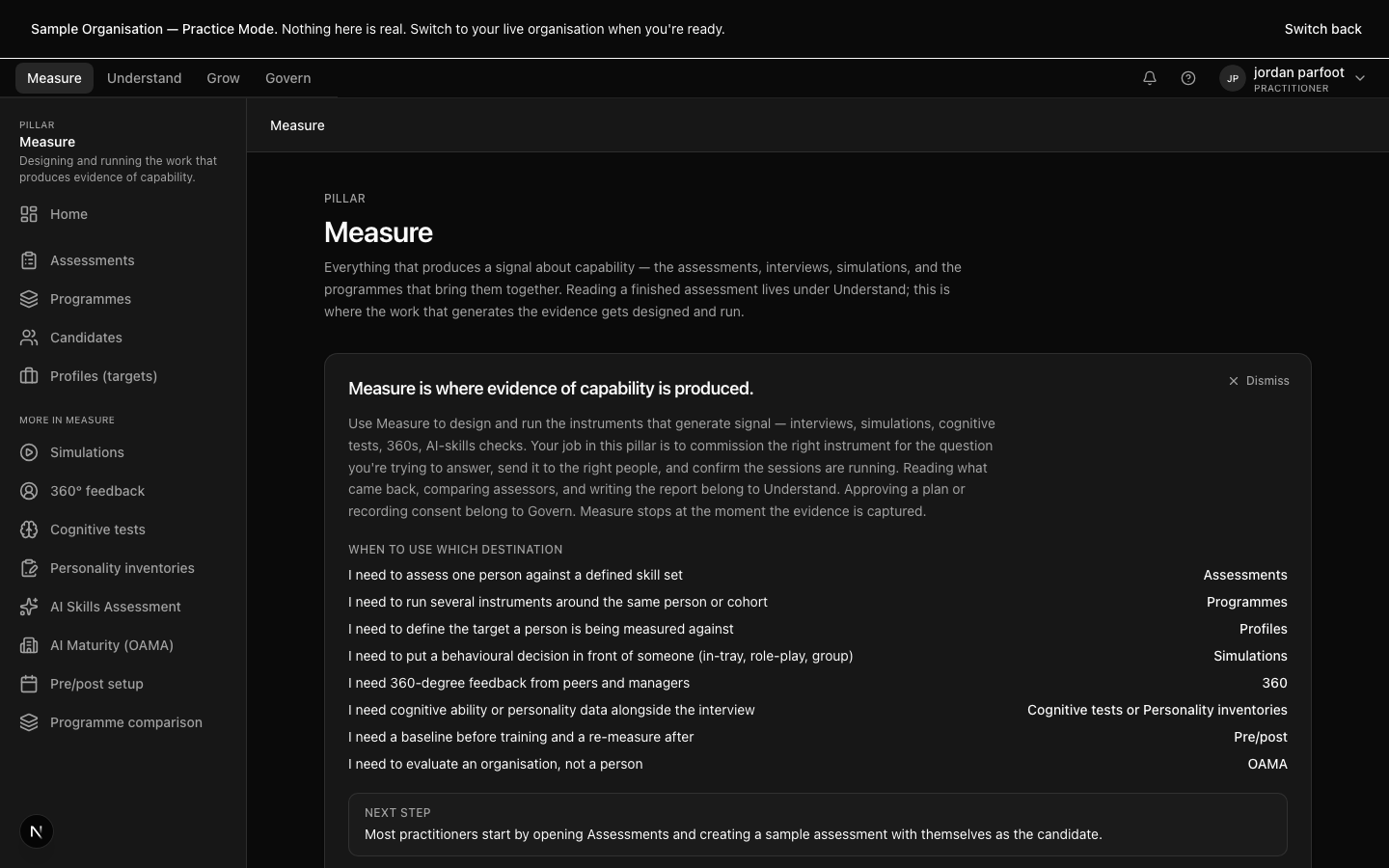
The Measure pillar overview — assessments in flight, programmes running, the instrument library, and the sign-off queue.
What Capable does for you
Capable gives you the surfaces to design assessments, run them across the instruments that fit the question, capture evidence in a shape your colleagues can also read, and sign off reports with the full provenance trail intact. The instrument library — structured interview, four kinds of simulation, cognitive ability, personality, 360-degree feedback, AI Skills (AISA), Organisational AI Maturity (OAMA), and pre/post measurement — sits inside programmes you orchestrate around one person or a cohort.
Calibration practice is a permanent affordance, not a one-off training module. You rate shared evidence against benchmark cases on a weekly cadence; the platform tracks where your judgement diverges from peer consensus and surfaces the items that would sharpen it. When you sign off a report, the defensibility bundle — consent record, evidence citations, sign-off chain, AI provenance, calibration history, contest activity — is one export away.
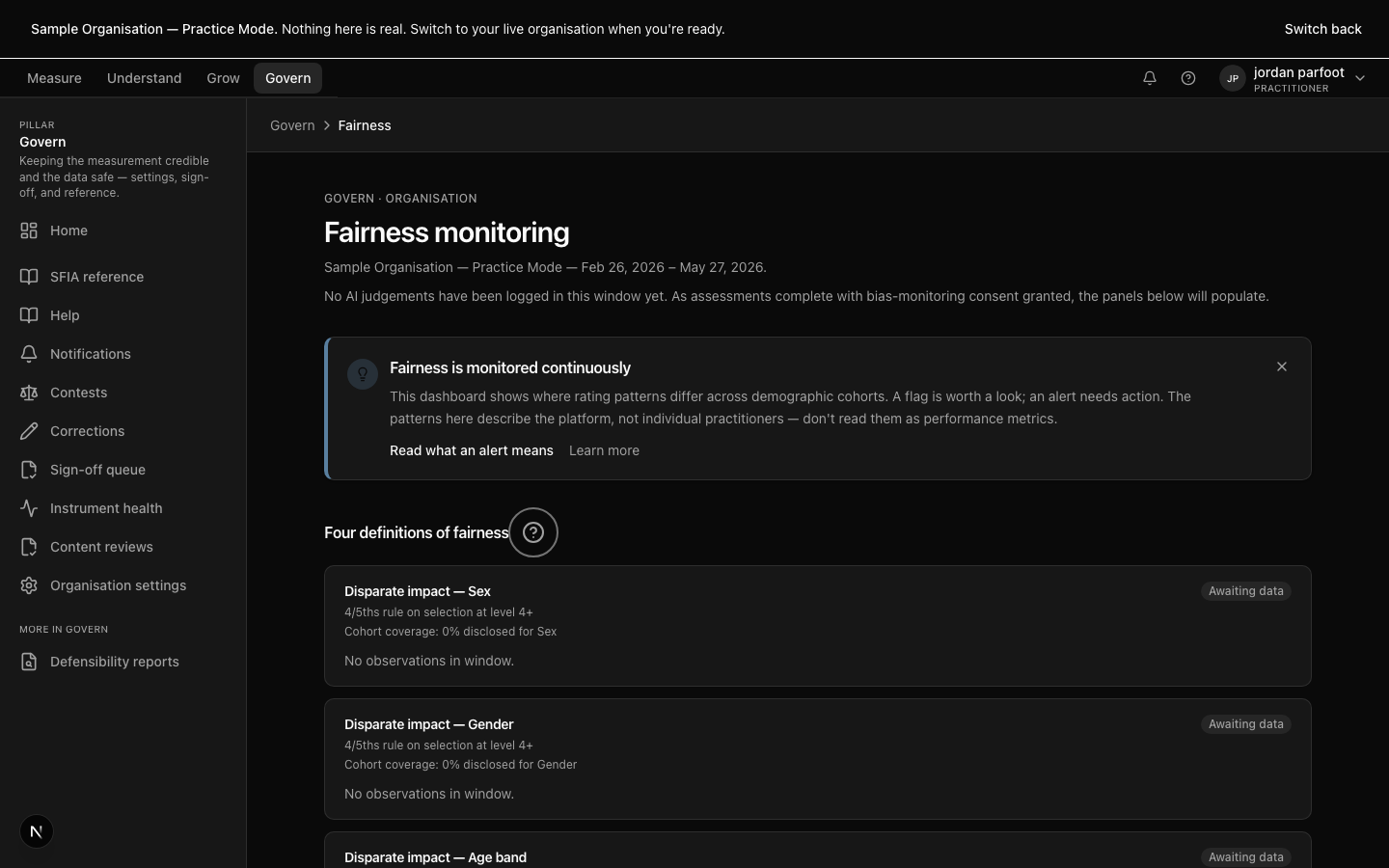
When a participant contests a rating, the appeals workflow surfaces on procedural-fairness rails. You see what they're contesting, what evidence they say was missed, and what additional examples they want considered. Your fairness dashboard sits on your own work, framed as checks on the platform's calibration — not as a performance metric on you. Sector overlays handle the register; thresholds remain platform-managed.
A typical journey
What progression usually looks like as you move from sandbox practice into real work and, eventually, into supporting newer practitioners.
- Day 1
Sandbox practice
Every new practitioner organisation arrives with a fictional sample organisation alongside the real one — sector-matched cohort, two programmes (one mid-flow, one signed off), a calibration set, a fairness signal at the flag threshold, and a participant appeal in flight. You run the full lifecycle end-to-end without touching a real person. Banner copy on every sandbox surface keeps the contexts unmistakable.
The single most important thing. You touch every joint of the platform — invite, review, draft, sign off, respond to an appeal — before any real participant sees your work.
- Week 1
Your first real participant work
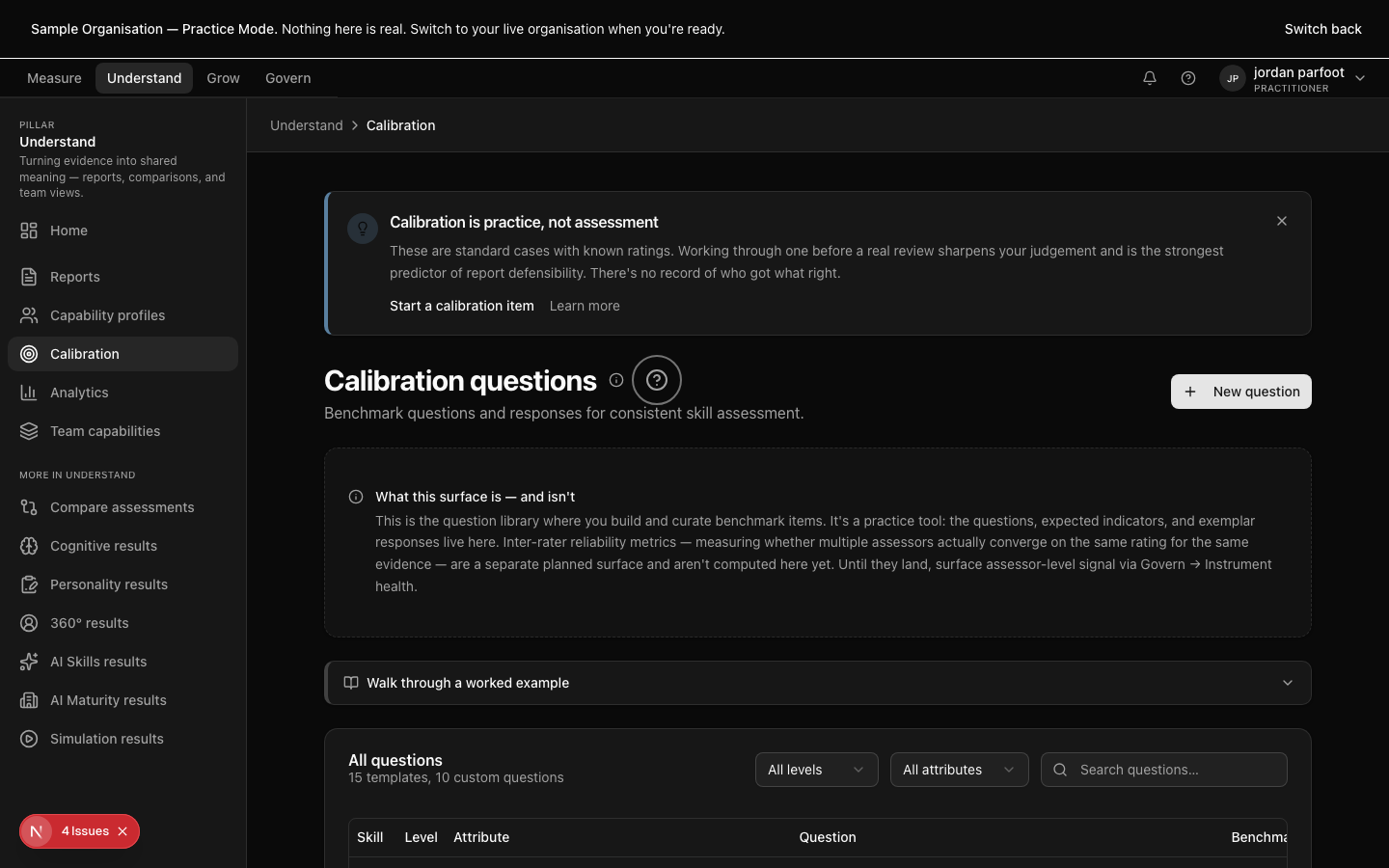
Calibration practice surfaces in your weekly flow — three items the platform has chosen because your judgement diverged from consensus on adjacent cases. The programme template gallery removes the blank-canvas problem when you're configuring multi-instrument work. Sector-keyed templates encode the instrument mix, sign-off chain, and consent shape your sector requires.
The single most important thing. Calibration is framed as professional development, not correction. Three items a week; the platform chooses which.
- Month 1
Contests, overrides, and fairness
By month one you're handling the Govern queues as routine work — contests, corrections, reassessment requests. The fairness dashboard on your own work surfaces as a contextual coaching card the first time it has something to say; never before. Fairness here is framed plainly: the platform is checking its own calibration on the evidence you reviewed.
The single most important thing. Fairness signals on your work are a check on the AI's calibration — never a performance metric on you.
- Power user (3+ months)
Reviewing newer practitioners
Coaching cards are all dismissed; command-K is muscle memory. What stays is the monthly practice summary — assessments run, sign-offs, consensus variance, appeals upheld, the calibration items most relevant to where your judgement diverged. A senior-practitioner affordance unlocks at this point: you can review the consensus of newer practitioners in your organisation, on cases they have flagged for a second look.
The single most important thing. Senior practitioners review consensus, not people. The affordance is opt-in and visible only to your organisation.
What you see, and what you don't
Scope is bounded by accountability. You see what you need to do the work; what you don't see is also part of the design.
What you see
- Assessments you have been assigned to, with the evidence inside them.
- Programmes you are responsible for, with the sign-off chain visible.
- Contests, corrections, and reassessment requests in your queues.
- Fairness signals on the work you have signed off, with sector-tuned bands.
- Your calibration history, with the items the platform has surfaced for you.
- Defensibility bundles for any assessment you have signed off.
What you don't see
- Assessments outside your organisation.
- Individual participant data without explicit consent.
- Other practitioners' calibration history without their permission.
- Trust & Safety oversight-level metrics — those sit with the T&S role.
Scope is bounded by accountability. Where consent unmasks individual data — for example, where a participant has shared their passport with you — the platform names the consent envelope the data came in under.
The surfaces you'll use
Five of the surfaces practitioners touch most — the pillar overview, the template gallery, calibration, fairness, and the defensibility bundle.
The Measure pillar overview — assessments in flight, programmes running, the instrument library.
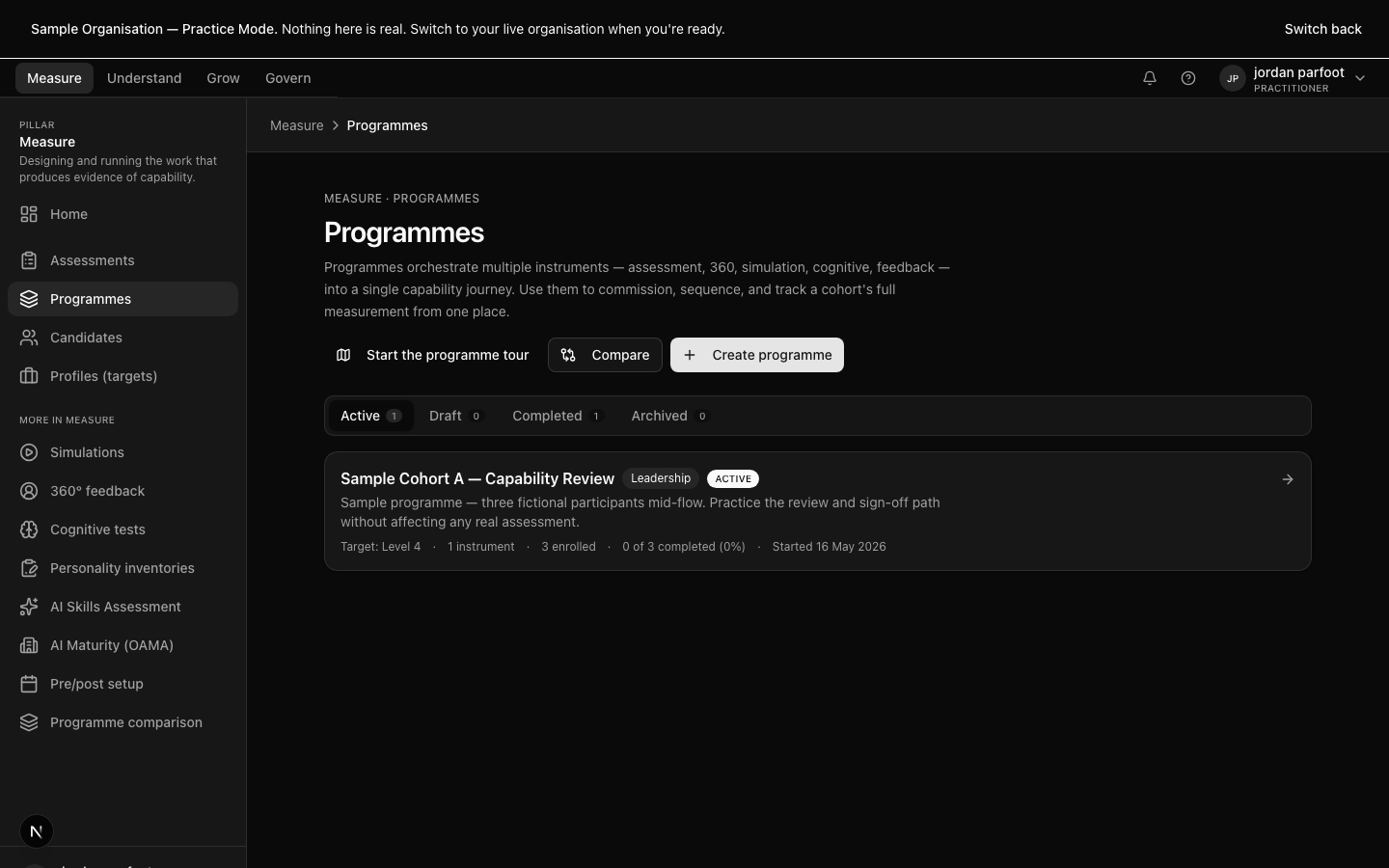
The programme template gallery — six sector-keyed templates with instrument mix and sign-off chain shown.
Calibration practice — three items surfaced this week based on where your judgement has diverged from consensus.
The fairness dashboard — per-attribute bias signals on your own work, with sector-tuned bands.
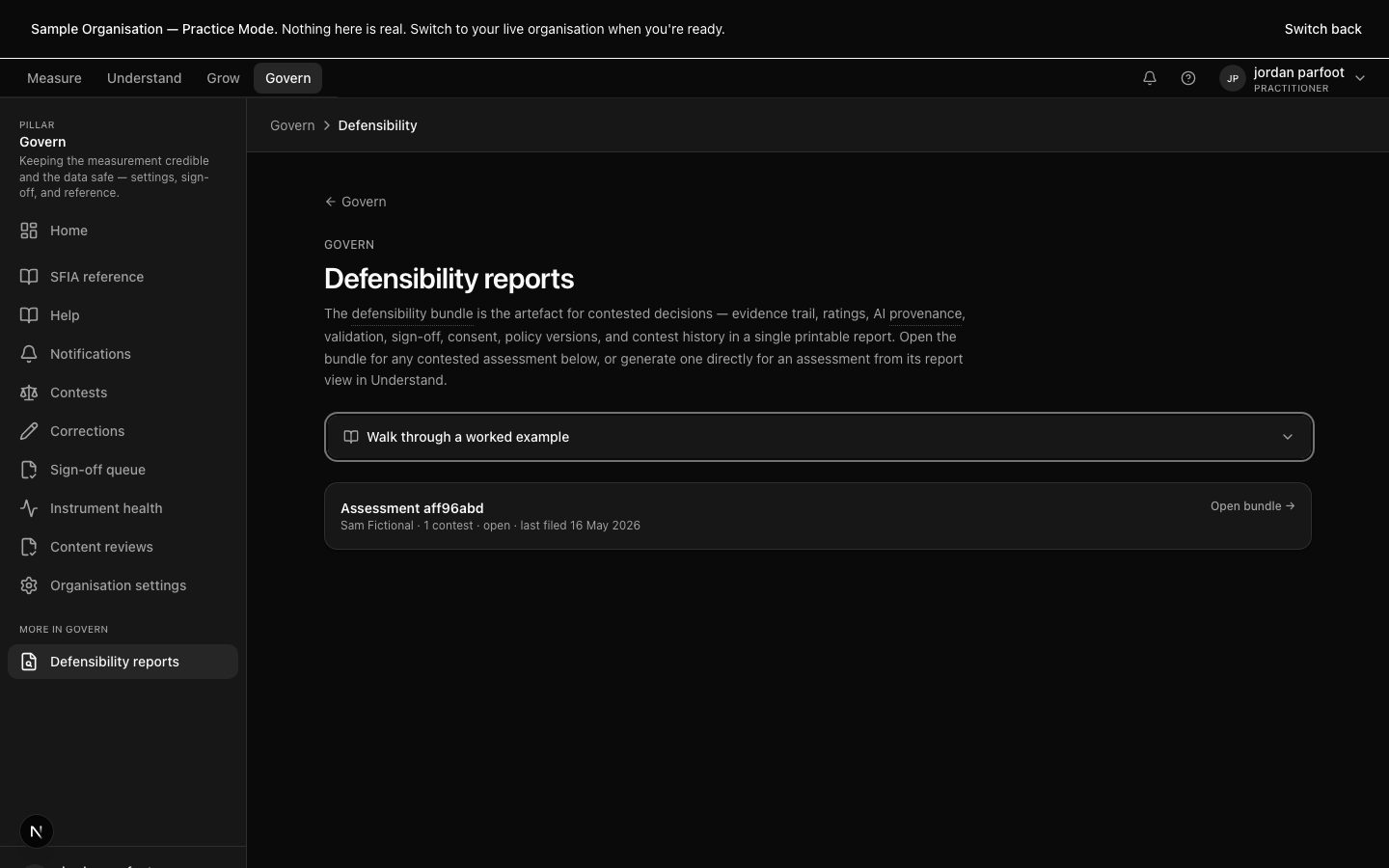
A defensibility bundle — consent record, evidence citations, sign-off chain, AI provenance, calibration history, contest activity.
See the practitioner surfaces against your sector
We walk through the practitioner surfaces on a deployment that matches your sector — your framework, your consent shape, your sign-off chain — rather than a generic demo.