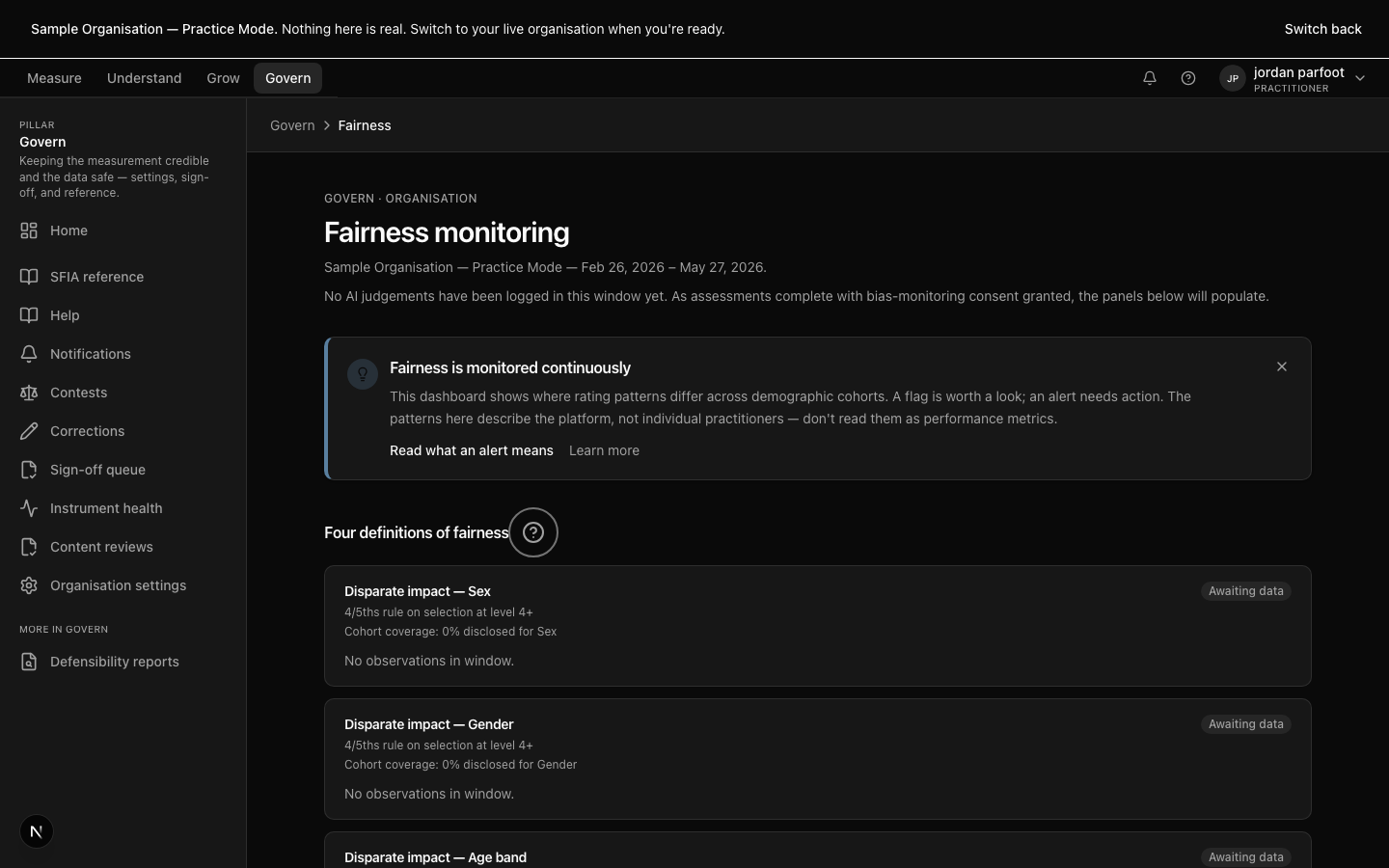
A rating you can defend
Every rating links to the specific evidence it rests on — no unmoored opinions reach a report. The AI drafts; a named practitioner signs off every release. When a rating is questioned, the platform produces the consent record, evidence citations, sign-off chain, and contest history in one export.
Ask for: a defensibility bundle for any signed assessment.