Reports
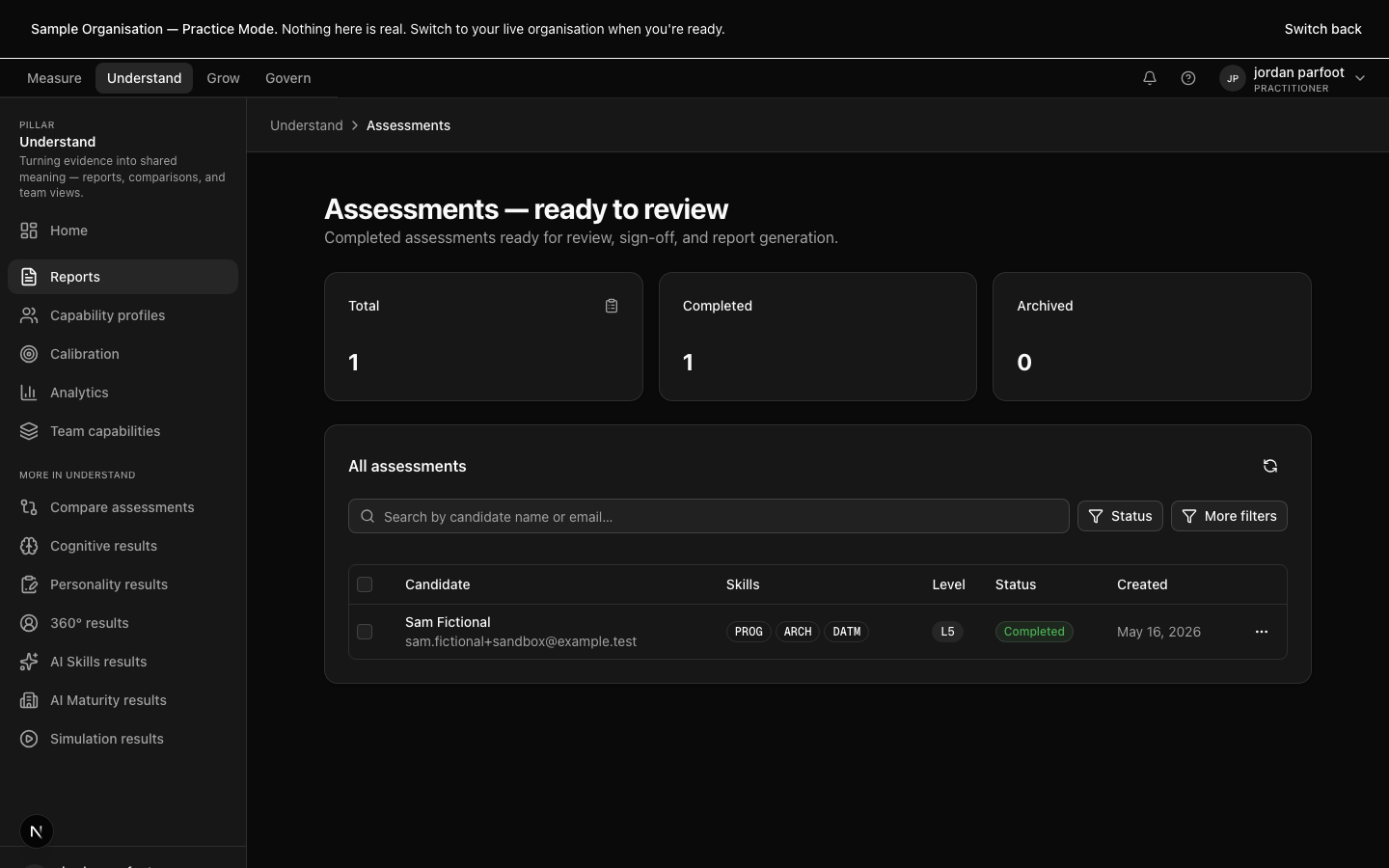
Read the finished assessment, examine the evidence, prepare it for sign-off.
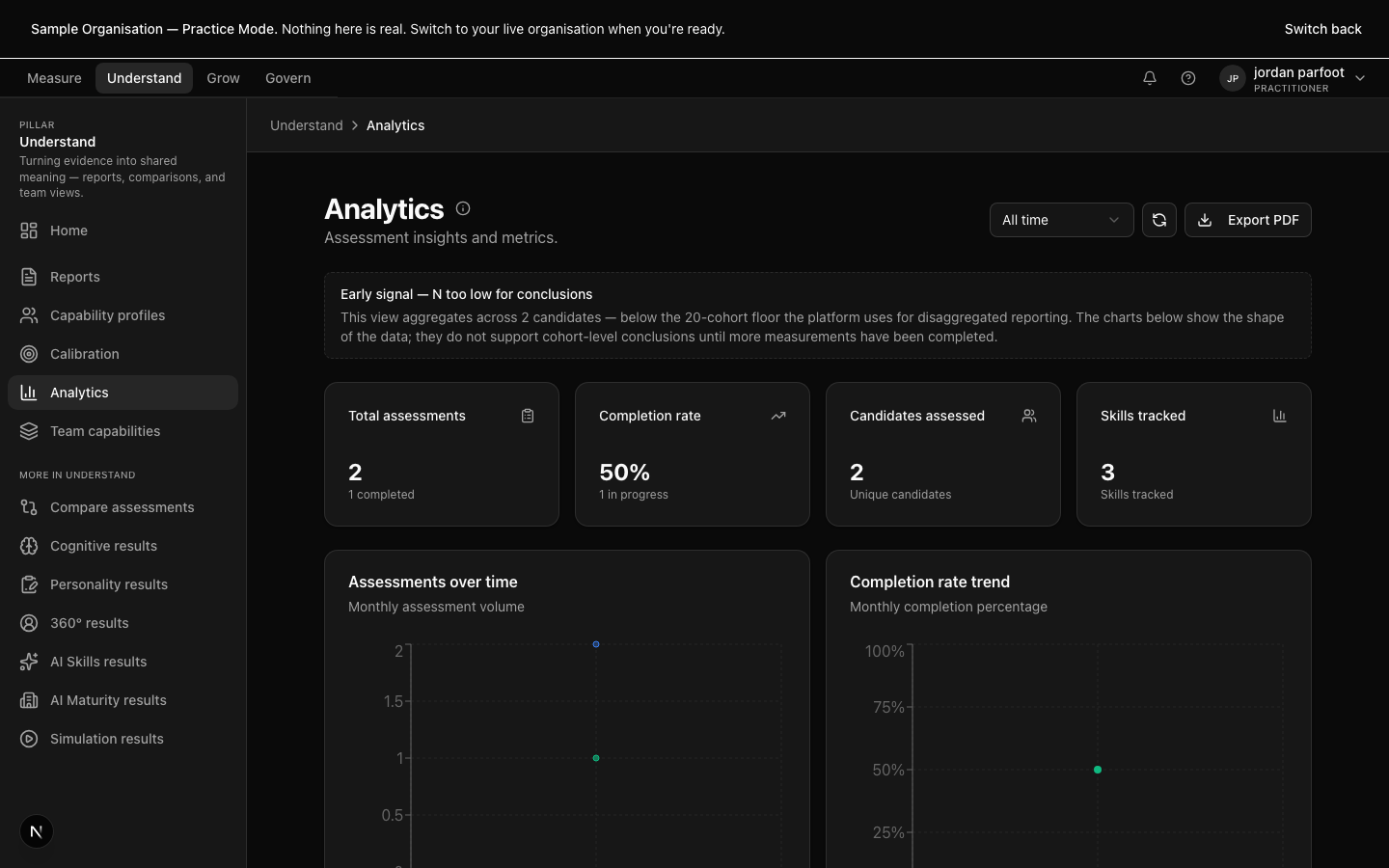
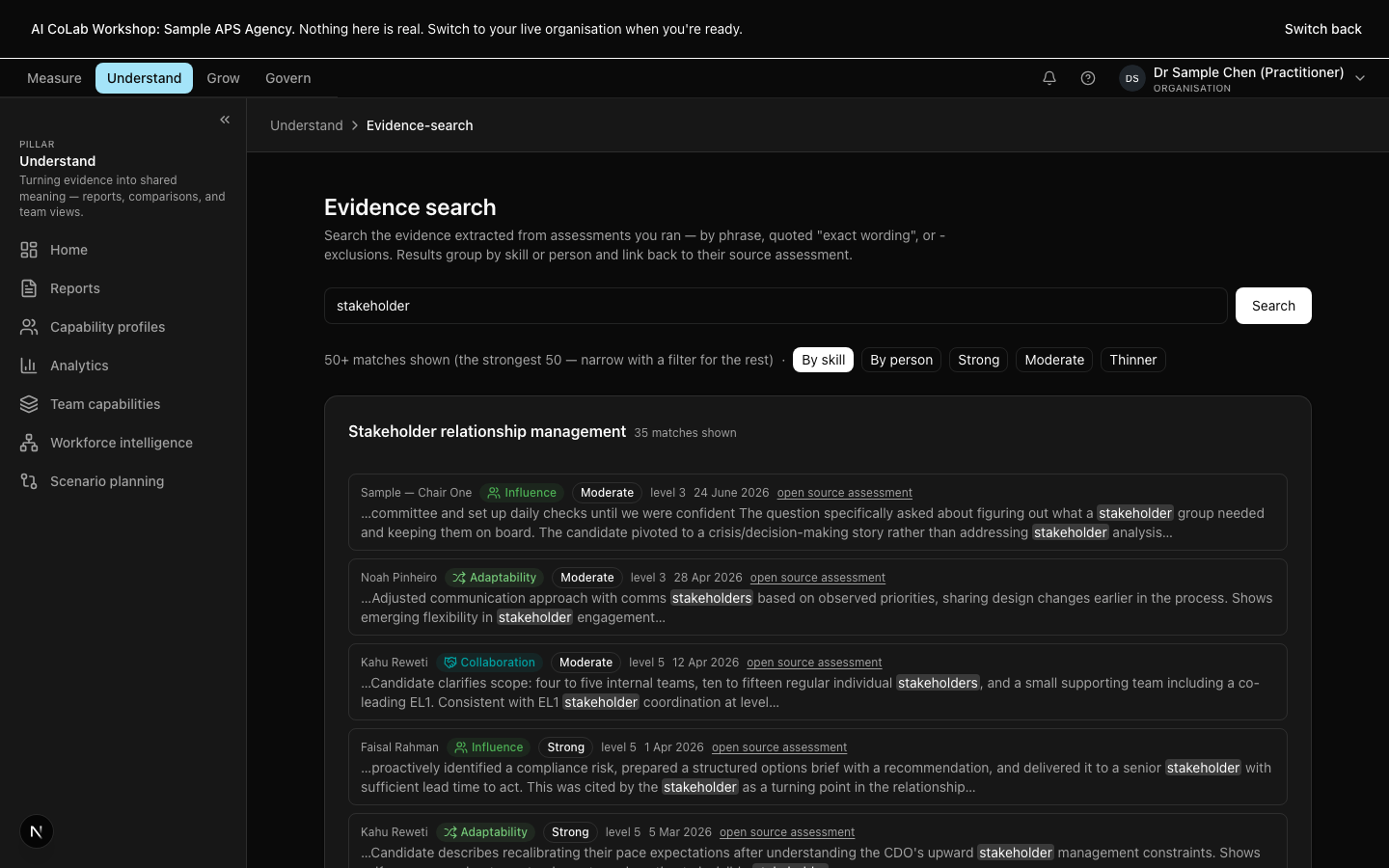
A report is the artefact a participant will see. The platform produces it strength-first — what the evidence shows the participant can do, then where the evidence is thinner and what the next level would look like. Every rating is linked to specific quotes, transcript moments, or simulation actions. There are no unmoored opinions in a Capable report.
Reports come in three variants from one source — the practitioner working view (with notes), the candidate view (without internal notes), and the signed-off view (locked at the moment of sign-off, hash-chained in the audit log). Comparing across the three is a one-click action; the practitioner never has to maintain a parallel document.
Reports — Read the finished assessment, examine the evidence, prepare it for sign-off.