Sign-off queue
Reports awaiting expert sign-off, with reviewer routing and SLAs.
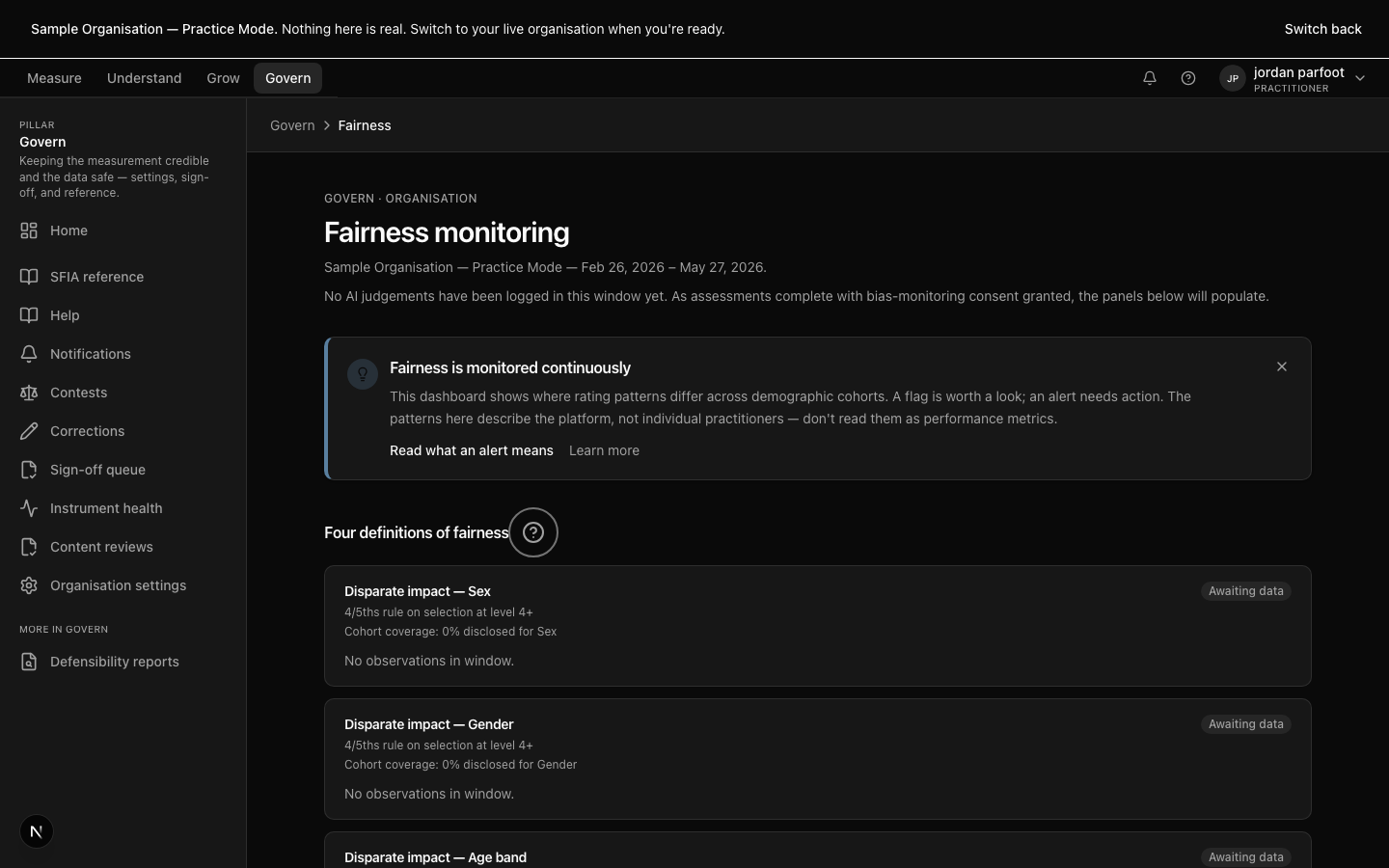
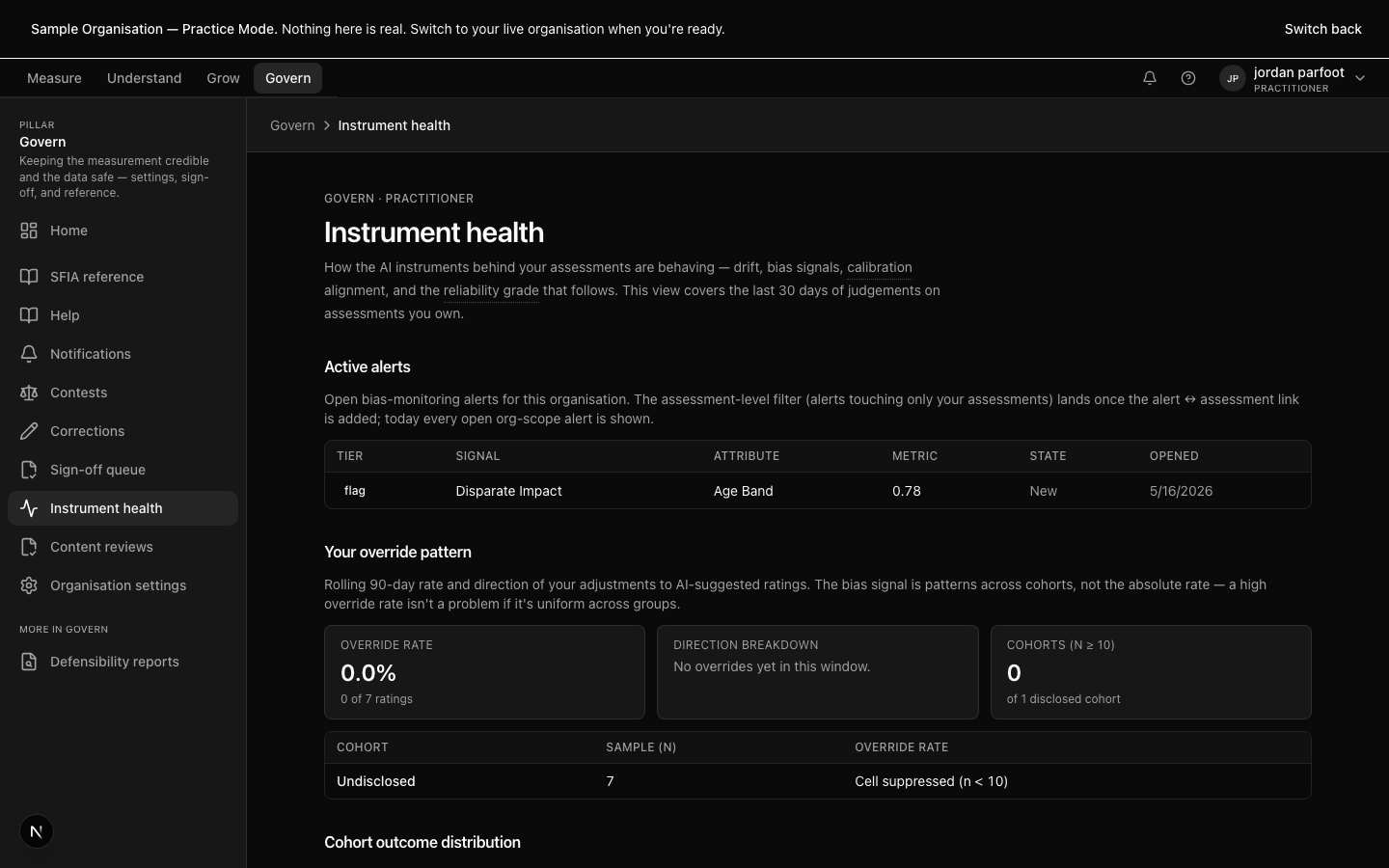
Sign-off is the moment a report leaves the working state and becomes a defensible artefact. The queue routes each report to the right reviewer, surfaces the evidence bundle and decision history, and locks the report's content into the audit trail at the moment of approval.
Sign-off is not a rubber stamp. The reviewer can request changes, return the report to the assessor, or escalate to an integration session if the dissent is material. The platform tracks the SLA; signed-off reports carry the reviewer's identity, the timestamp, and the hash.
Sign-off queue — Reports awaiting expert sign-off, with reviewer routing and SLAs.